부호화란?
어플리케이션에서는 메모리에 데이터를 저장할 때 객체, 구조체, 배열 등의 구조로 저장한다. 보통 CPU가 효율적으로 접근할 수 있도록 ‘포인터'를 사용하는데, 이는 다른 언어를 사용하는 프로세스에서는 이해하지 못할 수 있다. 그러므로 데이터를 파일에 쓰거나 네트워크로 전송하려면 바이트 형태로 저장한다.
- 부호화: 인메모리 → 바이트 (직렬화, 마샬링)
- 복호화: 바이트 → 인메모리 (역직렬화, 언마샬링, 파싱)
정리하면, 데이터 부호화는 통신 주체(프로세스 또는 서버)가 다른 언어의 데이터 구조를 사용해도 상대 프로세스가 이해할 수 있도록 데이터를 전환하는 것을 말한다. 더 쉽게 말하면 어플리케이션 환경에 구애받지 않는 데이터 형식으로 전환하는 과정을 말한다.
데이터 부호화, 왜 알아야 하는가
데이터부호화 형식에 따라 human-readable(사람이 읽기에 좋은), 데이터 압축률(가용성 증가, 통신 성능 증가), 호환성 유지에 영향을 줄 수 있다.
호환성 유지
어플리케이션은 계속 변경된다. 그에 따라 데이터 모델도 변경된다. 데이터 모델을 변경하는 과정에서 어플리케이션이 중지되지 않고 계속 돌아가기 위해서는 상위호환성과 하위호환성을 지켜야 한다.
- 하위호환성: 새로운 코드가 이전 코드에서 기록한 데이터를 읽을 수 있어야 함
- 상위호환성: 이전 코드가 새로운 코드에서 기록한 데이터를 읽을 수 있어야 함(새로 추가된 필드는 못읽겠지만 적어도 읽는 데 오류가 없어야 함)
데이터 부호화 형식
언어별 형식
- Java : java.io.Serializable
- Ruby : Marshal
- Python : pickle
편리하지만 문제점도 많다.
- 다른 언어와 호환되지 않아 다른 시스템과 통합할 때 방해될 수 있음.
- 보안 문제.
- 상위/하위 버전 호환 문제.
- 효율성
- Java의 내장 직렬화는 성능이 좋지 않은 것으로 유명.
GitHub - eishay/jvm-serializers: Benchmark comparing serialization libraries on the JVM
Benchmark comparing serialization libraries on the JVM - GitHub - eishay/jvm-serializers: Benchmark comparing serialization libraries on the JVM
github.com
JSON과 XML, 이진 변형
JSON, XML, CSV는 많은 프로그래밍 언어에서 읽고 쓸 수 있는 표준화된 부호화이다.
JSON, XML, CSV의 문제점들
- number 인코딩이 애매하다.
- number인지 숫자로 구성된 문자열인지 구분할 수 없음.
- JSON은 숫자와 문자열을 구분할 수 있지만, 정수와 부동소수점 수를 구별하지 않고 정밀도를 지정하지 않는다.
- 큰 수를 다룰 때 문제 발생 가능성.
- 2^53(대략 9천조)보다 큰 정수는 IEEE 754 배정도 부동소수점 수에서는 정확히 표현할 수 없음.
- 이진 문자열(문자 부호화가 없는 바이트열)을 지원하지 않는다.
- XML과 JSON은 스키마를 지원하지만, 학습과 구현이 어렵다.
- JSON 기반 도구는 스키마 사용을 강제하지 않는다.
- json schema 만드는 법은 json schema 문서를 참고한다.
- CSV는 스키마가 없어, 각 로우와 컬럼의 의미를 애플리케이션에서 정의해야 한다.
- CSV의 특정 값에 쉼표나 개행 문자가 포함되었다면? 이처럼 CSV는 모호한 형식이다.
이진부호화
조직내에서만 사용하는 데이터라면 최소공통분모 부호화 형식을 사용해야 하는 부담감이 덜하다.
즉, 더 간편하고 파싱이 빠른 형식을 쓸 수 있습니다.
테라바이트 정도 되면 데이터 타입의 선택이 큰 영향을 미친다.
json으로 바이트 변환을 하면 기존의 json 형식과 바이트차이가 크지 않다.
ex) 메세지팩으로 부호화하여도 바이트수가 큰 차이가 없다.
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming","hacking"]
}
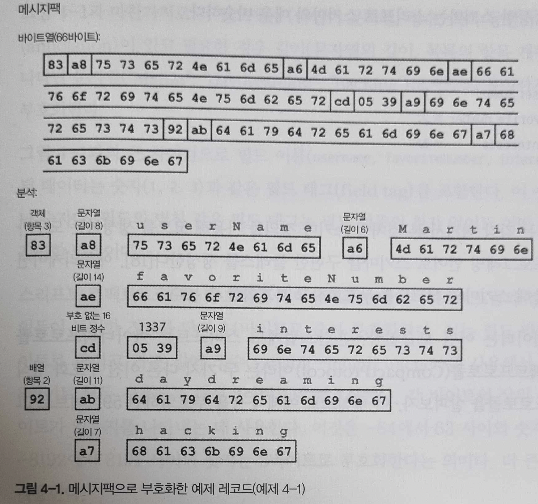
과연 가독성을 해칠 만큼 가치가 있을까? 확실하지 않다.
이보다 더 잘 할 수 있는 방법을 살펴 본다.
스리프트와 프로토콜 버퍼(Thrift and Protocol Buffers)
이진 인코딩 라이브러리
- 페이스북에서 개발한 Apache Thrift
- 구글에서 개발한 protocol buffers
thrift, protocolbuffer(줄여서 protobuf)같은 경우는 비슷하게 생겼다.
둘 다 RPC(remote process call) 프레임워크이다. thrift가 지원하는 언어가 더 많다. protocolbuffer의 경우 grpc에서 사용되고 있으며 압축률이 좋아 성능을 높일 수 있다. thrift 역시 컴팩트 프로토콜의 경우 protocolbuffer와 압축률이 비슷하다, protocolbuffer는 grpc에서 사용되고 있다.
둘다 데이터를 위한 스키마가 필요하다.
thrift는 struct, protobuf는 message로 인터페이스를 정의한다.
struct Person {
1: required string UserName,
2: optional i64 favoriteNumber,
}
message Person {
required string user_name = 1;
optional i64 favorite_number = 2;
}
이렇게 인터페이스로 스키마를 정의하는 언어를 IDL이라고 한다.
아무튼 thrift와 protobuf 둘 다 인덱스가 붙어있는 걸 볼 수 있는데 이 때문에 필드 중간에 새 필드를 추가하거나 기존 필드를 삭제하면 호환성에 문제가 생길 수도 있다. 그럼 굳이 왜 인덱스를 붙이느냐? 인덱스를 부여함으로써 성능을 높일 수 있다.
thrift
바이너리 프로토콜, 컴팩트 프로토콜 두 가지 이진 부호화 방식을 가진다.
thrift 스키마를 보면 필드에 숫자가 부여된 것을 볼 수 있다.
메시지팩 같은 경우는 필드 이름 또한 그대로 바이트로 변환하여 데이터 크기를 줄이는 데 별 효과가 없었다.
하지만 thrift의 경우 필드 이름을 숫자로 대체할 수 있게 되어 데이터 크기를 줄이는 데 효과적이다.
바이너리 프로토콜의 경우 각 필드는 타입, 필드 태그(인덱스), 데이터 길이, 값의 바이트로 되어있다.
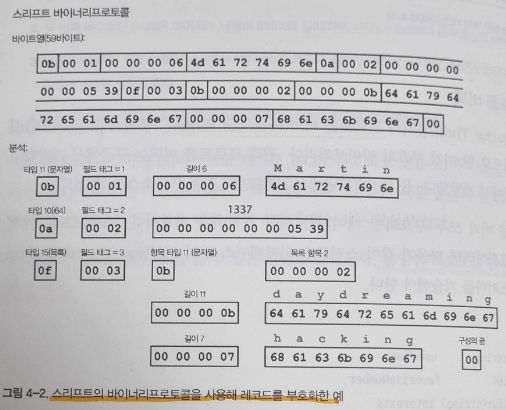

protocolbuffer
비트를 줄이고 저장하는 처리 방식은 약간 다르지만 부호화된 데이터를 보면 컴팩트 프로토콜과 비슷하다.
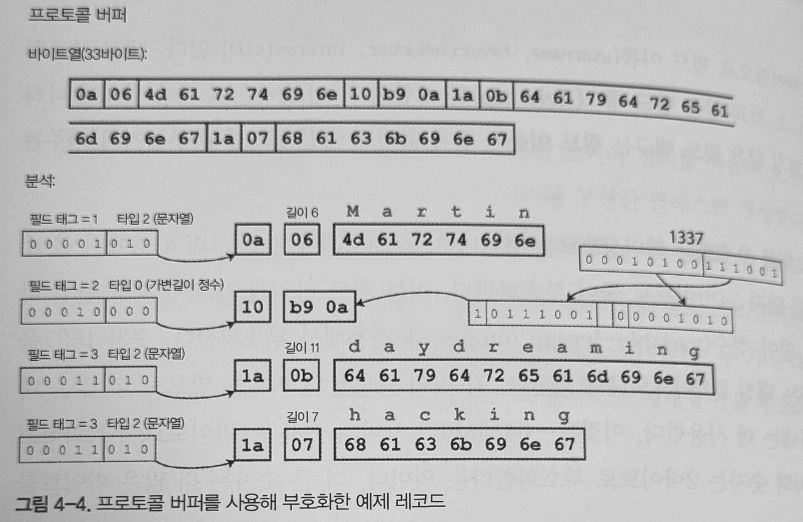
압축률도 비슷하지만 프로토콜 버퍼가 조금 더 성능이 좋은 듯 하다.
압축률
- 메시지팩: 81 → 66 바이트
- 바이너리 프로토콜: 81 → 59 바이트
- 콤팩트 프로토콜: 81 → 34 바이트
- 프로토콜 버퍼: 81 → 33 바이트
스키마는 필연적으로 시간이 지남에 따라 변한다. 이를 스키마 발전 이라 한다.
스리프트와 프로토콜 버퍼는 하위,상위 호환성을 어떻게 유지할까?
필드에 새로운 태그 번호를 부여하는 방식으로 스키마에 새로운 필드를 추가할 수 있다.
- 상위호환성 유지: 예전코드가 인식할 수 없는 코드를 읽으려고 하면 건너뛰면서 간단히 무시할 수 있다. 필드 삭제는 optional만 가능하다.
- 하위호환성 유지: 새로운 코드는 예전 데이터를 항상 읽을 수 있다. 그러나 새로운 필드를 required로 추가하면 이전 데이터를 읽는 작업이 실패한다. 하위호환성 유지하려면 스키마의 초기 배포 이후에 모든 필드는 optional로 하거나 기본값을 가져야 한다. 필드 삭제는 간단히 건너 뛸수 있다.
아브로(Avro)
또 하나의 이진 부호화 형식이다. 아브로는 스키마에 태그 번호가 없다. 이 스키마를 이용해서 부호화하면 길이가 가장 짧다.하여 정확한 데이터 타입을 미리 파악해야 한다.
그렇다면 아브로는 어떻게 스키마 발전을 제공할까?
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null","long"], "default": null},
{"name": "interests","type": {"type": "array","items": "string"}}
]
}
쓰기 스키마와 읽기 스키마
- file, db, network를 통해 전송 목적으로 부호화하기 위해 사용
- application이 빌드하는 동안 스키마 생성
- 쓰기, 읽기의 스키마가 다를 수 있다. 또한 필드의 순서가 달라도 문제 없다
- 없는 필드를 만드면 이 필드를 무시후 기본값으로 채운다
아보로 스키마 발전 규칙
- 상위 호환
- 새로운 버젼의 쓰기 스키마와 예전 버전의 읽기 스키마를 가질 수 있음
- 필드 이름 변경 불가
- 하위 호환(예전 데이터를 지금도 읽을 수 있다)
- 새로운 버젼의 읽기 스키마와 예전 버젼의 쓰기 스키마를 가질 수 있다
- 필드 이름 변경을 추적할 수 있기 때문에 필드 이름 변경 가능
이러한 호환성을 유치하기 위해 default 가 있는 필드만 추가 삭제 가능예전 스키마에 없는 값이 읽기 스키마에 있으면 기본값으로 대체 즉 아브로는 스키마가 동적으로 변경될 가능성을 고려하여 설계됨
코드 생성과 동적 타입언어
- 스리프트와 프로토컬 버퍼는 코드 생성에 의존
- Java, C++, C# 같은 정적 타입 언어에서 유용
- 스키마가 변경되면 재컴파일 필요 avro는 compile, interpreter 언어를 선택해 사용할 수 있다.
- 아브로는 정적 타입 프로그래밍 언어를 위해 코드 생성을 선택적으로 제공
- 객체 컨테이너 파일이 있다면 라이브러리를 이용하여 json파일 보는거 처럼 볼수 있다.
스키마의 장점
- protocol buffers, Thrift, Avro는 스키마를 사용해 이진 인코딩 형식을 기술한다.
- 이 스키마 언어는 XML/JSON 스키마보다 심플하며 더 자세한 유효성 검사 규칙을 지원한다.
이진 인코딩의 좋은 특징
- 인코딩된 데이터에서 필드 이름을 생략 가능하여, 사이즈가 작다.
- 스키마는 유용한 문서 형식.
- 스키마 DB를 유지하여, 상위/하위 호환성을 확인할 수 있다.
- 정적 타입 프로그래머 언어 사용시에 유용.
데이터플로 모드(Modes of Dataflow)
- 데이터플로는 매우 추상적인 개념.
- 하나의 프로세스에서 다른 프로세스로 데이터를 전달하는 방법은 매우 많다.
다음은 가장 보편적인 (메모리를 공유하지 않는) 프로세스 간 데이터 전달 방법이다.
- 데이터베이스를 통해서
- 서비스 호출을 통해서
- 비동기적 메시지 전달을 통해서
데이터베이스를 통한 데이터플로
- 데이터베이스에 기록하는 프로세스는 데이터를 부호화하고 읽는 프로세스는 복호화한다
- 단일프로세스로 DB에 접근
- DB에 저장하는 일은 미래의 자신에게 메시지를 보내는 일
- 하위 호환성이 분명히 필요
- 다양한 프로세스가 DB에 접근
- 흔한 방식의 application이나 서비스
- 순회식으로 배포를 한다면 새로운 버젼을 배포하는 몇몇 instance 는 예전 코드로 데이터를 저장하고 갱신중일 것
- 상위 호환성이 필요
- 부호화는 모르는 필드는 건들지 않지만 DB 관점에선 데이터가 유실될 수 있다.
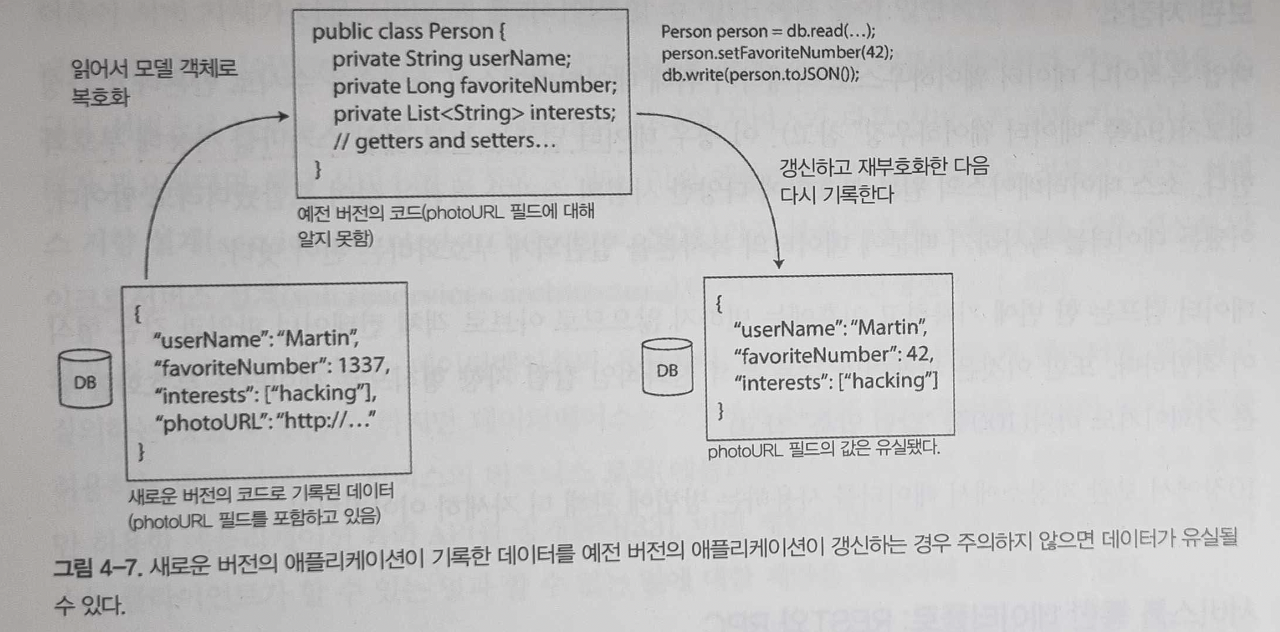
- 데이터베이스의 값은 언제나 갱신 가능하고 데이터가 코드보다 더 오래 산다.
- 스키마를 변경하고 마이그레이션 하는 작업은 비싼 작업이라서 대부분의 데이터 베이스는 기본적으론 간단한 스키마 변경을 허용한다.
- 링크드인 문서 데이터베이스인 에스프레소는 아브로 스키마 발전 규칙을 사용하기 위해 문서를 저장할 때 아브로를 사용한다.
서비스를 통한 데이터플로: REST와 RPC
클라이언트와 서버
- 서버 : 네트워크를 통해 API를 공개한다.
- 서버가 공개한 API를 서비스라 부른다.
- 클라이언트 : API로 요청을 만들어 서버에 연결할 수 있다.
SOA
서버 자체가 다른 서비스의 클라이언트일 수 있다 (예를 들어 일반적인 웹 앱 서버는 데이터베이스의 클라이언트로 동작한다). 이런 접근 방식은 보통 대용량 애플리케이션의 기능 영역을 소규모 서비스로 나누는 데 사용한다. 예를 들어 하나의 서비스가 다른 서비스의 일부 기능이나 데이터가 필요하다면 해당 서비스에 요청을 보낸다. 이런 애플리케이션 개발 방식을 전통적으로는 서비스 지향 설계(service-oriented architecture, SOA)라고 불렀으며 최근에는 이를 더욱 개선해 마이크로서비스 설계(microservices architecture)란 이름으로 재탄생했다.
SOA, MSA의 핵심 설계 목표
서비스를 배포와 변경에 독립적으로 만들어 애플리케이션 변경과 유지보수를 더 쉽게 할 수 있게 만드는 것이다. 예를 들어 각 서비스는 한 팀이 소유해야 하고 해당 팀은 다른 팀과의 조정 없이 자주 서비스의 새로운 버전을 출시할 수 있어야 한다. 다시 말해 예전 버전과 새로운 버전의 서버와 클라이언트가 동시에 실행되기를 기대한다. 따라서 서버와 클라이언트가 사용하는 데이터 부호화는 서비스 API의 버전 간 호환이 가능해야 한다.
웹 서비스
- 웹 서비스에는 대중적인 두 가지 방법인 REST와 SOAP가 있다.
- 이 둘은 철학적인 측면에서 거의 정반대의 입장.
REST(Representational State Transfer)
- REST는 프로토콜이 아니라 HTTP의 원칙을 토대로 한 설계 철학이다.
- REST는 간단한 데이터 타입을 강조한다.
- URI을 사용해 리소스를 식별하고 캐시 제어, 인증, 콘텐츠 유형 협상에 HTTP 메소드를 사용한다.
- REST 원칙에 따라 설계된 API를 RESTful이라 부른다.
- RESTful API는 간단한 접근 방식을 선호한다.
- 코드 생성기와 자동화된 도구가 없어도 가능한 접근 방식을 선호.
- RESTful API는 간단한 접근 방식을 선호한다.
SOAP(Simple Object Access Protocol)
- 네트워크 API 요청을 위한 XML 기반 프로토콜.
- SOAP 웹 서비스의 API는 WSDL이라 부르는 XML 기반 언어를 사용해 기술한다.
- WSDL은 사람이 읽을 수 있게 설계하지 않았고, 복잡하므로 IDE/코드 생성 도구에 의존한다.
- SOAP 벤더가 지원하지 않는 프로그래밍 언어의 경우 SOAP 서비스와의 통합이 어렵다.
- HTTP와 독립적이며, HTTP 메소드 대부분을 사용하지 않는다.
- 대신, 다양한 기능을 추가한 여러 관련 표준 프레임워크를 제공한다.
- 주의: 줄임말이 비슷하긴 하지만 SOAP는 SOA의 요구사항이 아니다.
- SOAP는 특정 기술이고, SOA는 시스템을 구축하는 방법론이다.
RPC
RPC(remote procedure call)로 원격 네트워크 서비스 요청을 같은 프로세스 안에서 특정 프로그래밍 언어의 함수나 메서드 호출하는 것과 동일하게 사용 가능하게 해준다.
RPC 현재방향
비동기 작업을 캡슐화하는 방향으로 가고 있고 gRPC는 일련의 요청과 응답을 받는 스트림을 지원한다.
RPC의 단점
- 네트워크 요청은 예측이 어렵다.
- 네트워크 문제는 일상적이다.
- 네트워크 함수 호출은 훨씬 느리다.
메시지 전달 데이터플로
RPC(Remote Procedure Call)와 DB간 비동기 메시지 시스템(asynchronous message passing system).
- 클라이언트 요청(메시지)을 낮은 지연 시간으로 다른 프로세스에 전달.
- 메시지를 직접 네트워크 연결로 전송하지 않고 중간 단계를 거쳐 전송.
- 중간 단계: 메시지 브로커(message broker), 메시지 큐(message queue).
- 중간 단계: 메시지 지향 미들웨어(message-oriented middleware).
메시지 브로커 사용 방식의 장점(RPC와 비교).
- 수신자가 사용 불가능하거나 과부하 상태일 때
- 메시지 브로커가 버퍼처럼 동작하여 시스템 안정성이 향상된다.
- 죽었던 프로세스에 메시지를 다시 전달할 수 있으므로, 메시지 유실을 방지할 수 있다.
- 송신자가 수신자의 IP 주소나 포트 번호를 알 필요가 없다.
- 하나의 메시지를 여러 수신자로 전송할 수 있다.
- 논리적으로 송신자는 수신자와 분리된다.
메시지 전달 통신은 일반적으로 단방향이라는 점이 RPC와 다르다. 즉 송신 프로세스는 대개 메시지에 대한 응답을 기대하지 않는다. 프로세스가 응답을 전송하는 것은 가능하지만 이것은 보통 별도 채널에서 수행한다. 이런 통신 패턴이 비동기다. 송신 프로세스는 메시지가 전달될 때까지 기다리지 않고 단순히 메시지를 보낸 다음 잊는다.
메시지 브로커(Message brokers)
상용으로 TIBCO, IBM WebSphere, webMethods 등이 있음.
오픈소스 구현으로는 RabbitMQ, ActiveMQ, HornetQ, NATS, Apache Kafka 등이 있다.
- 프로세스 하나가 메시지를 이름이 지정된 queue나 topic으로 전송한다.
- 브로커는 해당 queue나 topic의 소비자(consumer) 또는 구독자(subscriber)에게 메시지를 전달한다.
- 동일한 토픽에 여러 생산자와 소비자가 있을 수 있다.
- topic은 단방향 데이터플로만 제공한다.
분산 액터 프레임워크(Distributed actor frameworks) - keyword: 비동기
- actor model
- 단일 프로세스 안에서 동시성을 위한 프로그래밍 모델.
- 스레드(경쟁조건, 잠금, 교착 상태와 연관된 문제들)를 직접 처리하는 대신 로직이 액터에 캡슐화된다.
- 각 액터는 하나의 클라이언트나 엔티티를 나타낸다.
- 액터는 로컬 상태를 가질 수 있다.
- 액터는 비동기 메시지의 송수신으로 다른 액터와 통신한다.
- 액터는 메시지 전달을 보장하지 않는다.
- 각 액터 프로세스는 한 번에 하나의 메시지만 처리한다.
- 스레드에 대해 걱정할 필요가 없음.
- 각 액터는 프레임워크와 독립적으로 실행 가능.
분산 액터 프레임워크는 기본적으로 메시지 브로커와 액터 프로그래밍 모델을 단일 프레임워크에 통합한다.
분산 액터 프레임워크
- Akka
- Orleans
- erlang
'프로그래밍 > Study정리' 카테고리의 다른 글
| 2장:데이터 중심 애플리케이션 설계 (0) | 2022.12.12 |
|---|---|
| 1장:데이터 중심 애플리케이션 설계 (2) | 2022.12.06 |


댓글